MS Robotics Studio sai de versão beta
A Microsoft lançou oficialmente o seu ambiente de desenvolvimento de softwares para robôs, o Microsoft Robotics Studio.
Com o software a companhia pretende se colocar no centro do cenário da robótica, licenciando seu sistema para outras empresas ou ainda curiosos e interessados na criação de robôs.
O uso não-comercial do programa será gratuito, porém aqueles que desejam utilizar a aplicação em projetos comerciais precisarão pagar uma taxa de licenciamento, a partir de US$ 399. A empresa diz que, a partir de sua interface drag and drop, até pessoas sem conhecimentos profundos de programação conseguirão criar um robô.
Uma ferramenta tridimensional permitirá aos desenvolvedores simular as ações, baseado no mecanismo licenciado PhysX, da Ageia Technologies. Programadores mais experientes poderão utilizar as linguagens do Visual Studio e Visual Studio Express (Visual C# e Visual Basic) para tornar seus sistemas mais eficientes, além da linguagem IronPython, da Microsoft.
A Microsoft já assinou contrato com mais de 30 outras empresas para oferecer compatibilidade com o seu software, entre elas a Lego, iRobot, RoboSoft, RoboticsConnection e Sharp Logic, com outras planejadas para um futuro próximo.
A ferramenta foi mostrada pela primeira vez em junho de 2006, e é uma aposta em um mercado que a empresa diz estar crescendo: a versão beta do programa teve mais de 100 mil downloads.
Com este tipo de ambientes, a Microsoft espera o surgimento de novas idéias. Uma tentativa semelhante está sendo feita com o XNA Game Studio Express, uma ferramenta criada para facilitar o desenvolvimento de jogos nas plataformas da empresa (Vista e Xbox 360).
A companhia afirmou que será uma das patrocinadoras do evento RoboCup 2007, que visa criar um time de robôs humanóides jogadores de futebol para enfrentar o campeão mundial até 2050.
Para baixar a primeira versão oficial da ferramenta, em inglês, basta acessar o site oficial do projeto em microsoft.com/robotics. O download, de aproximadamente 47 MB, está disponível sob o item "Download & Licensing" do menu.
15.12.06
4.12.06
AMD demonstra quad core nativo
O fabricante de microprocessadores demonstrou em público um Opteron com quatro núcleos de processamento integrados. A Intel conseguiu ser o primeiro fabricante a disponibilizar processadores quad core, mas fê-lo juntando dois chips dual core no mesmo package. A AMD demonstrou agora um Opteron de quatro núcleos nativos (integrados no mesmo chip), com o nome de código “Barcelona”. A grande vantagem da arquitectura nativa é o menor consumo energético. Segundo a AMD, os Opteron quad core vão consumir entre 68 watts e 125 watts e deverão estar disponíveis em meados de 2007. Fonte: Exame Informática |
2.12.06
Hacks Gerais: Gmail
Uma situação recorrente quando estamos num local qualquer a usar um PC que não seja o nosso é querermos guardar informação (afinal, baseia-se tudo na partilha de informação).
O facto de querermos guardar informação gera um problema: ou estamos ligados à web e temos acesso a um servidor de partilha de ficheiros ou temos uma pen drive.
O facto de podermos enviar um email já nem se coloca, pois a maior parte dos servidores de email limita o tamanho dos ficheiros e, no caso do Gmail, os executáveis são mesmo filtrados, obrigando a alterar a extensão do ficheiro a enviar. O caso da pen drive também é preocupante... pode-se perder, ou até mesmo ficar debaixo do rodado de um camião ;-)
Bom, a informação que vou divulgar já não é nova, mas nunca tinha sido abordada nos Engenheiros Web, portanto, aí vai.
É possível transformar a conta do Gmail num disco rígido, que permite arrastar, colar, cortar, criar pastas e organizar ficheiros, como que de uma pen drive online com 2.7 Gb se tratasse.
Bom, em primeiro lugar, é necessário aceder ao site de um tipo simpático que inventou o software.
Acedemos a http://www.viksoe.dk/code/gmail.htm e fazemos o download do executável.
Bom, assim que estiver instalado (é bastante rápido) é só aceder a 'O Meu Computador' e aparecerá uma nova drive com o nome de 'Gmail Drive'.
Agora, é só clicar com o botão direito na drive e fazer login (preenchendo o user Gmail e a password).
Possivelmente, da primeira vez que se acede, irá surgir uma mensagem de erro que diz que o Gmail está a bloquear esse software... bem, é só fazer novamente login e fica tudo a funcionar!
Finalmente, podemos começar a usar a drive... o melhor de tudo, é que podemos continuar à mesma a utilizar o Gmail como caixa de correio; os documentos enviados via 'O Meu Computador' são registados como sendo um email com a extensão 'fs' ou 'file system' no assunto.
Ainda mais! Os executáveis deixam de ser bloqueados e é muito mais rápido passar ficheiros (em princípio, até 10Mb corre tudo bem).
E sempre é possível criar um endereço Gmail, partilhar a password, o user e o software com mais amigos passando-se a ter uma drive partilhada na web de uma forma bastante rápida.
Cumprimentos.
O facto de querermos guardar informação gera um problema: ou estamos ligados à web e temos acesso a um servidor de partilha de ficheiros ou temos uma pen drive.
O facto de podermos enviar um email já nem se coloca, pois a maior parte dos servidores de email limita o tamanho dos ficheiros e, no caso do Gmail, os executáveis são mesmo filtrados, obrigando a alterar a extensão do ficheiro a enviar. O caso da pen drive também é preocupante... pode-se perder, ou até mesmo ficar debaixo do rodado de um camião ;-)
Bom, a informação que vou divulgar já não é nova, mas nunca tinha sido abordada nos Engenheiros Web, portanto, aí vai.
É possível transformar a conta do Gmail num disco rígido, que permite arrastar, colar, cortar, criar pastas e organizar ficheiros, como que de uma pen drive online com 2.7 Gb se tratasse.
Bom, em primeiro lugar, é necessário aceder ao site de um tipo simpático que inventou o software.
Acedemos a http://www.viksoe.dk/code/gmail.htm e fazemos o download do executável.
Bom, assim que estiver instalado (é bastante rápido) é só aceder a 'O Meu Computador' e aparecerá uma nova drive com o nome de 'Gmail Drive'.
Agora, é só clicar com o botão direito na drive e fazer login (preenchendo o user Gmail e a password).
Possivelmente, da primeira vez que se acede, irá surgir uma mensagem de erro que diz que o Gmail está a bloquear esse software... bem, é só fazer novamente login e fica tudo a funcionar!
Finalmente, podemos começar a usar a drive... o melhor de tudo, é que podemos continuar à mesma a utilizar o Gmail como caixa de correio; os documentos enviados via 'O Meu Computador' são registados como sendo um email com a extensão 'fs' ou 'file system' no assunto.
Ainda mais! Os executáveis deixam de ser bloqueados e é muito mais rápido passar ficheiros (em princípio, até 10Mb corre tudo bem).
E sempre é possível criar um endereço Gmail, partilhar a password, o user e o software com mais amigos passando-se a ter uma drive partilhada na web de uma forma bastante rápida.
Cumprimentos.
29.11.06
Quad-core em 2006?

Ao contrário do que acontece normalmente, a Intel antecipou o lançamento dos processadores com quatro núcleos. os processadores quad core estavam previstos para o primeiro trimestre de 2007, mas o seu lançamento foi antecipado para o último trimestre de 2006. Estes processadores são conhecidos pelo nome de código “Kentsfield” para desktop e “Clovertown” para servidores. Os Quad-core da Intel, são compostos por dois chips de 2 núcleos num só processador, do mesmo modo que o Pentium D tem dois chips de um núcleo em um só processador. Levando em conta o desempenho dos Pentium D, não devemos esperar grande coisa. Já a AMD está prometendo um verdadeiro Quad-core, com quatro núcleos em um só chip, para a metade de 2007. Se a história entre o Pentium D e os Athlon64 X2 se repetir, a AMD deve alcançar a liderança dos quad-core assim que o seu processador de quatro núcleos for lançado.
1.11.06
Firefox 2.0
Browsers
Firefox 2.0 lançado hoje
A nova versão do browser da Mozilla tem ferramentas anti-phishing e corrector ortográfico. O Firefox 2.0 vai iniciar hoje o segundo capítulo do duelo com o “gigante” Internet Explorer, cuja versão 7.0 foi lançada na semana passada.
Os responsáveis da Mozilla afirmam que o novo browser vem preparado para dar seguimento às exigências típicas dos internautas da segunda geração da Internet (Web 2.0). O lançamento deverá ocorrer durante o dia de hoje (durante esta manhã ainda não era possível descarregar o Firefoz 2.0 no site do browser).
Entre os principais atractivos do Firefox 2.0, encontra-se uma ferramenta que restaura páginas web acidentalmente fechadas pelos utilizadores ou por um qualquer colapso do computador.
Uma ferramenta que alerta o utilizador para a presença de técnicas de phishing nos sites que visita e um corrector ortográfico que pode ser utilizado em sites que permitem inserir texto são outras das funcionalidades a ter em atenção.
A estas ferramentas, o Firefox junta ainda capacidades de poliglota: o novo browser da Mozilla vai ser disponibilizado em 36 idiomas – um número bem acima do Internet Explorer 7 (IE7) que, por enquanto, apenas está disponível em inglês.
Mas há mais diferenças entre IE7 e Firefox 2.0: o primeiro é um produto criado seguindo os trâmites e processos da maior “fábrica de software” (a Microsoft); o segundo foi iniciado por uma organização sem fins lucrativos que dá pelo nome de Mozilla e recebeu o contributo de cerca de um milhão de programadores, que se voluntariaram sob a lógica do software livre.
Hoje, o Firefox 2.0 contém mais de 1900 funcionalidades criadas pela comunidade de programadores voluntários, informa a BBC. Actualmente, a quota de mercado do Firefox está fixada em 15%, segundo a estimativas mais optimistas.
O novo browser vai ser disponibilizado num site próprio .
Noticia de 24/10/2006 Clix
Post Original de Henrique
Firefox 2.0 lançado hoje
A nova versão do browser da Mozilla tem ferramentas anti-phishing e corrector ortográfico. O Firefox 2.0 vai iniciar hoje o segundo capítulo do duelo com o “gigante” Internet Explorer, cuja versão 7.0 foi lançada na semana passada.
Os responsáveis da Mozilla afirmam que o novo browser vem preparado para dar seguimento às exigências típicas dos internautas da segunda geração da Internet (Web 2.0). O lançamento deverá ocorrer durante o dia de hoje (durante esta manhã ainda não era possível descarregar o Firefoz 2.0 no site do browser).
Entre os principais atractivos do Firefox 2.0, encontra-se uma ferramenta que restaura páginas web acidentalmente fechadas pelos utilizadores ou por um qualquer colapso do computador.
Uma ferramenta que alerta o utilizador para a presença de técnicas de phishing nos sites que visita e um corrector ortográfico que pode ser utilizado em sites que permitem inserir texto são outras das funcionalidades a ter em atenção.
A estas ferramentas, o Firefox junta ainda capacidades de poliglota: o novo browser da Mozilla vai ser disponibilizado em 36 idiomas – um número bem acima do Internet Explorer 7 (IE7) que, por enquanto, apenas está disponível em inglês.
Mas há mais diferenças entre IE7 e Firefox 2.0: o primeiro é um produto criado seguindo os trâmites e processos da maior “fábrica de software” (a Microsoft); o segundo foi iniciado por uma organização sem fins lucrativos que dá pelo nome de Mozilla e recebeu o contributo de cerca de um milhão de programadores, que se voluntariaram sob a lógica do software livre.
Hoje, o Firefox 2.0 contém mais de 1900 funcionalidades criadas pela comunidade de programadores voluntários, informa a BBC. Actualmente, a quota de mercado do Firefox está fixada em 15%, segundo a estimativas mais optimistas.
O novo browser vai ser disponibilizado num site próprio .
Noticia de 24/10/2006 Clix
Post Original de Henrique
28.10.06
Windows Media Player 11
Instalei recentemente a beta version do Windows Media Player 11. Em termos visuais está interessante e aparentemente é menos esquisito com ficheiros media duvidosos retirados da web - pelo menos não me crasha tantas vezes...
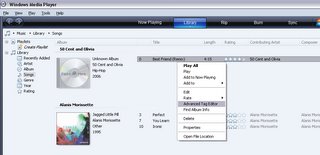
Um detalhe importante que é necessário realçar é o aparente desaparecimento do Editor Avançado de Tags que acompanhava as versões anteriores.
Com um clique do botão direito num ficheiro em reprodução (através do painel 'Em reprodução') conseguia aceder rapidamente ao Editor Avançado de Tags que, em substituição das Propriedades Avançadas - editáveis no próprio ficheiro, via Windows - permitia alterar informações sobre a música, autor, intérprete ... e até adicionar a letra (caso de um ficheiro de áudio se tratasse).
Bom, descobri hoje que afinal o Editor Avançado de Tags (EAT) não desapareceu do Windows Media Player 11, mas foi sim recolocado noutro local.
Para aceder ao mesmo, é necessário seleccionar a tab Library e nesse ecrã já é possível aceder ao EAT com o famoso right-button click no ficheiro pretendido.
Parabéns Bill, podias era ter avisado!
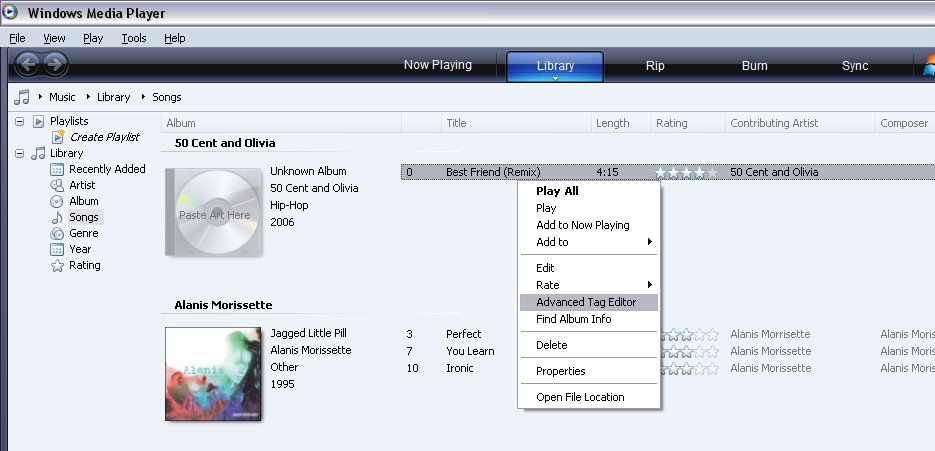
Um detalhe importante que é necessário realçar é o aparente desaparecimento do Editor Avançado de Tags que acompanhava as versões anteriores.
Com um clique do botão direito num ficheiro em reprodução (através do painel 'Em reprodução') conseguia aceder rapidamente ao Editor Avançado de Tags que, em substituição das Propriedades Avançadas - editáveis no próprio ficheiro, via Windows - permitia alterar informações sobre a música, autor, intérprete ... e até adicionar a letra (caso de um ficheiro de áudio se tratasse).
Bom, descobri hoje que afinal o Editor Avançado de Tags (EAT) não desapareceu do Windows Media Player 11, mas foi sim recolocado noutro local.
Para aceder ao mesmo, é necessário seleccionar a tab Library e nesse ecrã já é possível aceder ao EAT com o famoso right-button click no ficheiro pretendido.
Parabéns Bill, podias era ter avisado!
20.10.06
Darwin
Curta: O Colégio de Cristo da Universidade de Cambrige começou a disponibilizar gratuitamente na internet as obras de Charles Darwin. A página principal é http://darwin-online.org.uk/.
27.9.06
Hardware: RAID
RAID, é a sigla de Redundant Array of Independent Disks e é basicamente um meio de se criar unidades virtuais, compostas por vários discos físicos independentes, com as funcionalidades de duplicação (redundância) ou balanceamento (operações de input e output em paralelo).
É uma tecnologia que combina vários discos rígidos para formarem uma única unidade lógica onde os dados são armazenados. Para o utilizador, não existem vários discos rígidos, mas sim um. A grande vantegem deste sistema é a tolerância a falhas pois, se um disco avariar, os outros continuam a funcionar (atenção que existem vários níveis de RAID).
Como é óbvio, a tecnologia RAID só faz sentido se existerem mais de dois discos rígidos.
Existem então três conceitos importantes para conhecermos em detalhe o RAID: mirroring, duplexing e data stripping.
1. Mirroring
É a forma pela qual fazemos um mirror (espelho) de um disco para outro; basicamente, é a execução de uma cópia de um disco para outro.
Ao ser feita uma escrita de dados no disco 1, os mesmos são também escritos no disco 2 (redundância dos dados).
Esta operação é excelente, caso um dos discos falhe, pois a informação começa a ser transferida do disco de suporte enviando um alerta ao administrador do sistema; o grande problema, é se a falha ocorrer no controlador dos discos, impedindo o acesso aos dois...
Por uma questão de optimização, as duas unidades de disco (o disco 1 e o disco 2) devem ter a mesma dimensão.
2. Duplexing
O duplexing é exactamente igual ao mirroring, com a excepção de ter um controlador por disco, aumentando assim a tolerância a falhas.
3. Data Stripping
Vamos supor que se tem um sistema com dois discos rígidos iguais: 80 Gb + 80 Gb.
Num sistema sem RAID, o acesso aos discos é feito de forma independente.
Ao dividirmos os dados, os dois discos farão parte do mesmo conjunto, criando um só disco virtual de 160 Gb (também não é assim tão linear, mas serve para exemplo). Ao gravar o ficheiro, o mesmo será partido em dois, sendo cada metade gravada em cada um dos discos físicos. O utilizador não tem qualquer intervenção neste processo.
Um dos maiores problemas nos sistemas é a velocidade de acesso aos discos. Com o RAID, este problema é resolvido.
Se tivermos um ficheiro com uma dimensão 2n e o quisermos gravar por inteiro num disco, ele ocupará um dado tempo t para o acesso, utilizando o único canal de comunicação disponível; mas, se tivermos dois discos em RAID, o ficheiro será dividido em dois ficheiros de dimensão n cada um e gravado em simultâneo nos dois discos, num intervalo de tempo t/2. Desta forma, a velocidade de acesso 'duplicou'!
Quantos mais discos tivermos, mais eficiente se tornará o sistema, e também mais caro...
O stripping do disco parte então os dados em pequenas porções e escreve-as em simultâneo em pequenas áreas denominadas stripes (tiras).
O stripping dos dados apenas aumenta a performance do sistema, não implementando tolerância a falhas.
Níveis de RAID:
RAID 0
Implementa o Data Stripping sem quaisquer métodos de segurança e integridade.
Como não tem qualquer tipo de redundância, se um disco avariar, os dados perdem-se.
Vantagens: é económico e não necessita de hardware de alta performance. Muito utilizado em sistemas com aplicações que necessitem de grande capacidade de armazenamento e acessos rápidos. Só é conveniente a sua utilização, caso exista um serviço de backup de dados.
RAID 1
Implementa o Mirroring.
Fornece dois métodos para optimizar a performance de leitura: round-robin schedulling e assigned cylinder schedulling.
No round-robin, os pedidos de leitura são alternados entre os discos; o segundo método permite dar a cada uma das unidades de disco a responsabilidade de cobrir metade do disco. Assim, os cilindros do disco são dividido em tantos sectores de 'responsabilidade' para as cabeças de leitura, quantos os discos que existirem.
O RAID fornece baixa performance de escrita mas uma excelente redundância dos dados.
RAID 2
Implementa o Data-Stripping com Detecção de Erros.
Distribui os dados pelas unidades de disco, utilizando um processo de detecção e correcção de erro.
Armazena informação ECC (Error Correcting Code), que é a informação de controle de erros.
RAID 3
É um Data-Stripping com uma técnica de recuperação de dados através de uma drive que armazena apenas bits de paridade.
Se tivermos RAID 3 com 3 discos (o ficheiro a graver será dividido em 3): os stripes 1 e 3 irão para o disco A; o stripe 2 irá para o disco B; o disco C armazena um bit de paridade que permitirá recuperar os dados caso um dos discos avarie.
Usa o menor tamanho possível para o stripe.
RAID 4
É semelhante ao RAID 3 mas implenta a distribuição dos dados ao nível de sectores ao invés de bytes (RAID 3).
É mais performante que o seu congénere e necessita de 3 ou mais discos iguais.
RAID 5
Igual aos anteriores mas, neste caso, todas as drives são do mesmo tamanho, uma das unidades fica inacessível ao Sistema Operativo e o bit de paridade é escrito em todas as drives.
Se tivermos 3 discos de 100 Gb, o espaço equivalente a um dos discos será reservado para os bits de paridade, disponibilizando apenas 200 Gb ao Sistema Operativo.
RAID 6
É uma actualização mais comercial do RAID 5.
Existe um disco adicional que entra em funcionamento caso um dos discos activos avarie.
RAID 10
Basicamente é RAID 0 + RAID 1 mas necessita de 4 discos rígidos.
Tipos de RAID:
Existem 2 tipos de RAID, sendo um baseado em hardware e o outro baseado em software.
O primeiro tipo é o mais utilizado, pois não depende do sistema operativo (pois estes visualizam um único disco grande) e são bastante rápidos, o que possibilita explorar integralmente seus recursos. A sua principal desvantagem é ser caro inicialmente.
O RAID baseado em hardware, utiliza dispositivos denominados "controladores RAID", que podem ser, inclusive, conectados nos slot da motherboard do computador.
O RAID baseado em software não é muito utilizado, pois apesar de ser mais barato, é mais lento, possui mais dificuldades de configuração e depende do sistema operativo para ter um desempenho satisfatório. O RAID por software ainda fica dependente das capacidades de processamento do computador em que é utilizado.
É uma tecnologia que combina vários discos rígidos para formarem uma única unidade lógica onde os dados são armazenados. Para o utilizador, não existem vários discos rígidos, mas sim um. A grande vantegem deste sistema é a tolerância a falhas pois, se um disco avariar, os outros continuam a funcionar (atenção que existem vários níveis de RAID).
Como é óbvio, a tecnologia RAID só faz sentido se existerem mais de dois discos rígidos.
Existem então três conceitos importantes para conhecermos em detalhe o RAID: mirroring, duplexing e data stripping.
1. Mirroring
É a forma pela qual fazemos um mirror (espelho) de um disco para outro; basicamente, é a execução de uma cópia de um disco para outro.
Ao ser feita uma escrita de dados no disco 1, os mesmos são também escritos no disco 2 (redundância dos dados).
Esta operação é excelente, caso um dos discos falhe, pois a informação começa a ser transferida do disco de suporte enviando um alerta ao administrador do sistema; o grande problema, é se a falha ocorrer no controlador dos discos, impedindo o acesso aos dois...
Por uma questão de optimização, as duas unidades de disco (o disco 1 e o disco 2) devem ter a mesma dimensão.
2. Duplexing
O duplexing é exactamente igual ao mirroring, com a excepção de ter um controlador por disco, aumentando assim a tolerância a falhas.
3. Data Stripping
Vamos supor que se tem um sistema com dois discos rígidos iguais: 80 Gb + 80 Gb.
Num sistema sem RAID, o acesso aos discos é feito de forma independente.
Ao dividirmos os dados, os dois discos farão parte do mesmo conjunto, criando um só disco virtual de 160 Gb (também não é assim tão linear, mas serve para exemplo). Ao gravar o ficheiro, o mesmo será partido em dois, sendo cada metade gravada em cada um dos discos físicos. O utilizador não tem qualquer intervenção neste processo.
Um dos maiores problemas nos sistemas é a velocidade de acesso aos discos. Com o RAID, este problema é resolvido.
Se tivermos um ficheiro com uma dimensão 2n e o quisermos gravar por inteiro num disco, ele ocupará um dado tempo t para o acesso, utilizando o único canal de comunicação disponível; mas, se tivermos dois discos em RAID, o ficheiro será dividido em dois ficheiros de dimensão n cada um e gravado em simultâneo nos dois discos, num intervalo de tempo t/2. Desta forma, a velocidade de acesso 'duplicou'!
Quantos mais discos tivermos, mais eficiente se tornará o sistema, e também mais caro...
O stripping do disco parte então os dados em pequenas porções e escreve-as em simultâneo em pequenas áreas denominadas stripes (tiras).
O stripping dos dados apenas aumenta a performance do sistema, não implementando tolerância a falhas.
Níveis de RAID:
RAID 0
Implementa o Data Stripping sem quaisquer métodos de segurança e integridade.
Como não tem qualquer tipo de redundância, se um disco avariar, os dados perdem-se.
Vantagens: é económico e não necessita de hardware de alta performance. Muito utilizado em sistemas com aplicações que necessitem de grande capacidade de armazenamento e acessos rápidos. Só é conveniente a sua utilização, caso exista um serviço de backup de dados.
RAID 1
Implementa o Mirroring.
Fornece dois métodos para optimizar a performance de leitura: round-robin schedulling e assigned cylinder schedulling.
No round-robin, os pedidos de leitura são alternados entre os discos; o segundo método permite dar a cada uma das unidades de disco a responsabilidade de cobrir metade do disco. Assim, os cilindros do disco são dividido em tantos sectores de 'responsabilidade' para as cabeças de leitura, quantos os discos que existirem.
O RAID fornece baixa performance de escrita mas uma excelente redundância dos dados.
RAID 2
Implementa o Data-Stripping com Detecção de Erros.
Distribui os dados pelas unidades de disco, utilizando um processo de detecção e correcção de erro.
Armazena informação ECC (Error Correcting Code), que é a informação de controle de erros.
RAID 3
É um Data-Stripping com uma técnica de recuperação de dados através de uma drive que armazena apenas bits de paridade.
Se tivermos RAID 3 com 3 discos (o ficheiro a graver será dividido em 3): os stripes 1 e 3 irão para o disco A; o stripe 2 irá para o disco B; o disco C armazena um bit de paridade que permitirá recuperar os dados caso um dos discos avarie.
Usa o menor tamanho possível para o stripe.
RAID 4
É semelhante ao RAID 3 mas implenta a distribuição dos dados ao nível de sectores ao invés de bytes (RAID 3).
É mais performante que o seu congénere e necessita de 3 ou mais discos iguais.
RAID 5
Igual aos anteriores mas, neste caso, todas as drives são do mesmo tamanho, uma das unidades fica inacessível ao Sistema Operativo e o bit de paridade é escrito em todas as drives.
Se tivermos 3 discos de 100 Gb, o espaço equivalente a um dos discos será reservado para os bits de paridade, disponibilizando apenas 200 Gb ao Sistema Operativo.
RAID 6
É uma actualização mais comercial do RAID 5.
Existe um disco adicional que entra em funcionamento caso um dos discos activos avarie.
RAID 10
Basicamente é RAID 0 + RAID 1 mas necessita de 4 discos rígidos.
Tipos de RAID:
Existem 2 tipos de RAID, sendo um baseado em hardware e o outro baseado em software.
O primeiro tipo é o mais utilizado, pois não depende do sistema operativo (pois estes visualizam um único disco grande) e são bastante rápidos, o que possibilita explorar integralmente seus recursos. A sua principal desvantagem é ser caro inicialmente.
O RAID baseado em hardware, utiliza dispositivos denominados "controladores RAID", que podem ser, inclusive, conectados nos slot da motherboard do computador.
O RAID baseado em software não é muito utilizado, pois apesar de ser mais barato, é mais lento, possui mais dificuldades de configuração e depende do sistema operativo para ter um desempenho satisfatório. O RAID por software ainda fica dependente das capacidades de processamento do computador em que é utilizado.
11.9.06
A grande engenharia sempre presente.
 O que é preciso é boa disposição para levarmos o barco a bom porto.
O que é preciso é boa disposição para levarmos o barco a bom porto.Uma imagem de dois dos nossos engenheiros tentando montar um sistema baseado num chip 555...
13.4.06
Visual Basic 2005
A Microsoft está a disponibilizar gratuitamente o livro Microsoft Visual Basic for Developers 2005 no seguinte site:
http://msdn.microsoft.com/vbrun/staythepath/additionalresources/introto2005/
Trata-se de um ficheiro executável que descarrega para o computador uma série de pdfs respeitantes aos vários capítulos do livro.
É mais uma prova de que nem tudo o que é Microsoft é mau e revela uma aproximação às publicações livres disponibilizadas online com um alto grau de fiabilidade e qualidade.
Esperamos que outras empresas e editoras comecem a fazer o mesmo.
Um aparte: a única forma de combater os downloads ilegais, é começar a ter este tipo de atitudes comerciais, disponibilizando informação gratuita na net.
http://msdn.microsoft.com/vbrun/staythepath/additionalresources/introto2005/
Trata-se de um ficheiro executável que descarrega para o computador uma série de pdfs respeitantes aos vários capítulos do livro.
É mais uma prova de que nem tudo o que é Microsoft é mau e revela uma aproximação às publicações livres disponibilizadas online com um alto grau de fiabilidade e qualidade.
Esperamos que outras empresas e editoras comecem a fazer o mesmo.
Um aparte: a única forma de combater os downloads ilegais, é começar a ter este tipo de atitudes comerciais, disponibilizando informação gratuita na net.
8.4.06
TCP-IP
A arquitectura TCP/IP surgiu por accção do Departamento de Defesa do governo dos Estados Unidos da América, com o objectivo principal de manter interligados orgãos do governo e universidades. A ARPANET, surgiu como uma rede que permaneceria intacta caso um dos servidores perdesse a conexão e, para isso, ela necessitava de protocolos que assegurassem tais funcionalidades trazendo confiabilidade, flexibilidade e facilidade de implementação. Foi desenvolvida então, a arquitectura TCP/IP. O modelo TCP/IP quando comparado com o modelo OSI, tem duas camadas que se formam a partir da fusão de algumas camadas: as camadas de Aplicação (Aplicação, Apresentação e Sessão) e Rede (Link de dados e Física).
Camada Aplicação:
É formada pelos protocolos utilizados pelas diversas aplicações do modelo TCP/IP. Esta camada não possui um padrão comum. O padrão é estabelecido por cada aplicação. Isto é, o FTP possui seu próprio protocolo, assim como o TELNET, SMTP, POP3, DNS, etc..
Camada Transporte:
Camada fim-a-fim, isto é, uma entidade desta camada só comunica com a sua entidade-par do host destinatário. É nesta camada que se faz o controle da conversação entre as aplicações intercomunicadas da rede. São utilizados dois protocolos: o TCP e o UDP. O TCP é orientado à conexão e o UDP não. O acesso das aplicações à camada de transporte é feito através de portas que recebem um número inteiro para cada tipo de aplicação.
Camada Internet:
(IP) Também conhecida como camada IP, é responsável pelo endereçamento, routing e controlo de envio e recepção. Não é orientada à conexão, comunicando através de datagramas.
Camada Rede:
Camada de abstração de hardware, tem como principal função a interface do modelo TCP/IP com os diversos tipos de redes (X.25, ATM, FDDI, Ethernet, Token Ring, Frame Relay, PPP e SLIP). Por causa da grande variedade de tecnologias de rede não é normalizada pelo modelo, o que possibililita interconexão e interoperação de redes heterogeneas.
O TCP é um protocolo da camada de transporte confiável; é baseado em conexão encapsulada no IP. O TCP garante a entrega dos pacotes, assegura o sequenciamento dos pacotes, e providencia um "checksum" que valida tanto o cabeçalho, como os dados do pacote. No caso da rede perder ou corromper um pacote TCP/IP durante a transmissão, é tarefa do TCP retransmitir o pacote perdido ou incorreto. Essa confiabilidade torna o TCP/IP o protocolo escolhido para transmissões baseadas em sessão, aplicações cliente-servidor e serviços críticos. Os cabeçalhos dos pacotes TCP requerem o uso de bits adicionais para assegurar o correcto sequenciamento da informação, bem como um "checksum" obrigatório para garantir a integridade do cabeçalho e dos dados. Para garantir a entrega dos pacotes, o protocolo requisita que o destinatário execute uma confirmação através do envio de um "acknowledgement", para que seja confirmada a recepção.
O protocolo UDP é a segunda opção da camada de transporte, sendo que ele não é confiável, pois não implementa "acknowledgements"," janelas", nem "sequenciamentos"; o único controlo feito é um "checksum" opcional que está dentro do seu próprio "header", utilizado por aplicações que não vão gerar altos volumes de tráfego na Internet. O IP é o protocolo da camada Internet. Ele é o encarregado da entrega de pacotes para todos os outros protocolos da família TCP/IP. Oferece um sistema de entrega de dados sem conexão. Ou seja, não garante que os pacotes cheguem ao destino, nem que sejam recebidos pela mesma ordem em que foram enviados. O "checksum" do IP confirma apenas a integridade do cabeçalho do pacote.
O endereço IP é formado por um número de 32 bits no formato "xxx.xxx.xxx.xxx" onde cada "xxx" pode variar de 0 até 255 (1 octeto = 8 bits). Os endereços possuem uma classificação que varia de acordo com o número de sub-redes e de hosts. Tal classificação tem por finalidade optimizar o routing de mensagens na rede.
Camada Aplicação:
É formada pelos protocolos utilizados pelas diversas aplicações do modelo TCP/IP. Esta camada não possui um padrão comum. O padrão é estabelecido por cada aplicação. Isto é, o FTP possui seu próprio protocolo, assim como o TELNET, SMTP, POP3, DNS, etc..
Camada Transporte:
Camada fim-a-fim, isto é, uma entidade desta camada só comunica com a sua entidade-par do host destinatário. É nesta camada que se faz o controle da conversação entre as aplicações intercomunicadas da rede. São utilizados dois protocolos: o TCP e o UDP. O TCP é orientado à conexão e o UDP não. O acesso das aplicações à camada de transporte é feito através de portas que recebem um número inteiro para cada tipo de aplicação.
Camada Internet:
(IP) Também conhecida como camada IP, é responsável pelo endereçamento, routing e controlo de envio e recepção. Não é orientada à conexão, comunicando através de datagramas.
Camada Rede:
Camada de abstração de hardware, tem como principal função a interface do modelo TCP/IP com os diversos tipos de redes (X.25, ATM, FDDI, Ethernet, Token Ring, Frame Relay, PPP e SLIP). Por causa da grande variedade de tecnologias de rede não é normalizada pelo modelo, o que possibililita interconexão e interoperação de redes heterogeneas.
O TCP é um protocolo da camada de transporte confiável; é baseado em conexão encapsulada no IP. O TCP garante a entrega dos pacotes, assegura o sequenciamento dos pacotes, e providencia um "checksum" que valida tanto o cabeçalho, como os dados do pacote. No caso da rede perder ou corromper um pacote TCP/IP durante a transmissão, é tarefa do TCP retransmitir o pacote perdido ou incorreto. Essa confiabilidade torna o TCP/IP o protocolo escolhido para transmissões baseadas em sessão, aplicações cliente-servidor e serviços críticos. Os cabeçalhos dos pacotes TCP requerem o uso de bits adicionais para assegurar o correcto sequenciamento da informação, bem como um "checksum" obrigatório para garantir a integridade do cabeçalho e dos dados. Para garantir a entrega dos pacotes, o protocolo requisita que o destinatário execute uma confirmação através do envio de um "acknowledgement", para que seja confirmada a recepção.
O protocolo UDP é a segunda opção da camada de transporte, sendo que ele não é confiável, pois não implementa "acknowledgements"," janelas", nem "sequenciamentos"; o único controlo feito é um "checksum" opcional que está dentro do seu próprio "header", utilizado por aplicações que não vão gerar altos volumes de tráfego na Internet. O IP é o protocolo da camada Internet. Ele é o encarregado da entrega de pacotes para todos os outros protocolos da família TCP/IP. Oferece um sistema de entrega de dados sem conexão. Ou seja, não garante que os pacotes cheguem ao destino, nem que sejam recebidos pela mesma ordem em que foram enviados. O "checksum" do IP confirma apenas a integridade do cabeçalho do pacote.
O endereço IP é formado por um número de 32 bits no formato "xxx.xxx.xxx.xxx" onde cada "xxx" pode variar de 0 até 255 (1 octeto = 8 bits). Os endereços possuem uma classificação que varia de acordo com o número de sub-redes e de hosts. Tal classificação tem por finalidade optimizar o routing de mensagens na rede.
2.4.06
Oracle - Criação da Base de Dados para Testes
Após instalar o Oracle 10g seguir os seguintes passos para a criação da BD de testes:
Start
All Programs
Oracle
Configuration and Migration Tools
DataBase Configuration Assistant
(demora um pouco a arrancar, não desesperem)
Painel Welcome
>Seguinte
Step 1
>Create a Database
>Seguinte
Step 2
>Custom Database
>Seguinte
Step 3
>Global Database Name = orcl10g
>SID = orcl10g
>Seguinte
Step 4
>Uncheck "Configure Database with Enterprise Manager"
>Seguinte
Step 5
>Use the same password
>Colocar a password
>Seguinte
Step 6
>Seleccionar File System
>Seguinte
Step 7
>Use common location C:\Oracle\Product\10.2.0
>Seguinte
Step 8
>Uncheck "Specify Flash Recovery Area" e "Enable Archiving"
>Seguinte
Step 9
>Uncheck de todas as opções e seleccionar "Standard Database Components"
>Seguinte
Step 10
>Typical
>Seguinte
Step 11
>Seguinte
Step 12
>Uncheck "Create Database"
>Check "Generate Database Creation Scripts"
>Terminar
Fazer OK no painel seguinte e escolher Terminar no último.
Start
All Programs
Oracle
Configuration and Migration Tools
DataBase Configuration Assistant
(demora um pouco a arrancar, não desesperem)
Painel Welcome
>Seguinte
Step 1
>Create a Database
>Seguinte
Step 2
>Custom Database
>Seguinte
Step 3
>Global Database Name = orcl10g
>SID = orcl10g
>Seguinte
Step 4
>Uncheck "Configure Database with Enterprise Manager"
>Seguinte
Step 5
>Use the same password
>Colocar a password
>Seguinte
Step 6
>Seleccionar File System
>Seguinte
Step 7
>Use common location C:\Oracle\Product\10.2.0
>Seguinte
Step 8
>Uncheck "Specify Flash Recovery Area" e "Enable Archiving"
>Seguinte
Step 9
>Uncheck de todas as opções e seleccionar "Standard Database Components"
>Seguinte
Step 10
>Typical
>Seguinte
Step 11
>Seguinte
Step 12
>Uncheck "Create Database"
>Check "Generate Database Creation Scripts"
>Terminar
Fazer OK no painel seguinte e escolher Terminar no último.
1.4.06
Hardware: Beep Code
Este guia visa analisar o código de beeps aquando do arranque do pc.
De uma forma geral, este código é comum a todas as marcas, mas por vezes existem variantes.
Em caso de dúvida, o ideal é ir directamente ao site do fabricante.
1 beep normal:
De uma forma geral, este código é comum a todas as marcas, mas por vezes existem variantes.
Em caso de dúvida, o ideal é ir directamente ao site do fabricante.
1 beep normal:
- Não é avaria, é o POST (Power On Self Test)
1 beep longo + 3 beeps curtos:
- Placa Gráfica
- Falta ligar o cabo do monitor
- VGA mal encaixada
- Problemas no slot de expansão
- Humidade nos contactos da VGA e/ou no Slot
- Falta de limpeza nos contactos da VGA (limpar os contactos com uma borracha de tinta)
- Problemas na BIOS da VGA
- VGA avariada
1 beep longo, infinito e pausado:
- Memória RAM
- Memória mal encaixada
- Problemas nos bancos de memória
- Falta de limpeza nos contactos das memórias (limpar os contactos com uma borracha de tinta)
- Humidade na memória e/ou nos bancos
- Módulos de Memória sobreaquecidos (deixar arrefecer as memórias e tentar mais tarde: se funcionar depois de estarem frias, utilizar um cooler de RAM)
- Memória avariada
Qualquer outro tipo de beeps e o pc não funciona:
- Motherboard
- Problemas na BIOS
- Problemas no Chipset da board
- Problemas nos chips da board
- Testar a CPU noutra board
Sem beeps e o pc não funciona:
- Speaker avariado
- Desligar todos os componentes e placas de expansão e testar uma a uma
- Mau isolamento da board
- Testar a board fora da caixa
- Motherboard ou CPU avariados
31.3.06
Windows: Prefetch
O Windows XP incorpora um novo modo de aceleração: o chamado "Prefetch". A ideia é muito básica mas eficaz: o Windows analisa quais os programas que são executados no arranque e quais os mais usados pelo utilizador e guarda-os em cache. Assim, da próxima vez que são executados, estão a ser executados parcialmente desde a cache, o que diminui consideravelmente o tempo de execução. Contudo, com o tempo, o lixo começa a apoderar-se do sistema e alguma da cache deixa de ser útil. Isso conduz directamente à perda de performance do sistema operativo.
A forma mais rápida de resolver isso é indo até à pasta C:\WINDOWS\PREFETCH e apagar tudo o que esteja lá dentro. No próximo arranque, o Windows deverá estar mais rápido outra vez (tanto quanto sei, esta operação só é possível no Windows XP).
Com o tempo, a pasta torna-se a encher de ficheiros inuteis. A única forma de resolver o problema de vez é desactivando parcial ou totalmente a colocação em cache (Prefetch). Para isso, a solução é ir ao Registry (Run > Regedit) e alterar a chave: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management\PrefetchParameters
Na chave EnablePrefetcher, é possível definir 4 valores diferentes:
0 - DESACTIVA por completo a colocação em cache. NÃO é recomendado.
1 - activa apenas para as aplicações usadas frequentemente pelo utilizador (acelera a respectiva execução).
2 - activa apenas para aplicações do arranque do Windows (acelera consideravelmente o arranque).
3 - activa totalmente a colocação em cache (é a definição por defeito)
Depois de definir o valor, é necessário reiniciar o computador para aplicar a nova definição (é recomendável apagar a pasta Windows\Prefetch depois da alteração.
A forma mais rápida de resolver isso é indo até à pasta C:\WINDOWS\PREFETCH e apagar tudo o que esteja lá dentro. No próximo arranque, o Windows deverá estar mais rápido outra vez (tanto quanto sei, esta operação só é possível no Windows XP).
Com o tempo, a pasta torna-se a encher de ficheiros inuteis. A única forma de resolver o problema de vez é desactivando parcial ou totalmente a colocação em cache (Prefetch). Para isso, a solução é ir ao Registry (Run > Regedit) e alterar a chave: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management\PrefetchParameters
Na chave EnablePrefetcher, é possível definir 4 valores diferentes:
0 - DESACTIVA por completo a colocação em cache. NÃO é recomendado.
1 - activa apenas para as aplicações usadas frequentemente pelo utilizador (acelera a respectiva execução).
2 - activa apenas para aplicações do arranque do Windows (acelera consideravelmente o arranque).
3 - activa totalmente a colocação em cache (é a definição por defeito)
Depois de definir o valor, é necessário reiniciar o computador para aplicar a nova definição (é recomendável apagar a pasta Windows\Prefetch depois da alteração.
26.3.06
Engenheiros Web, the beggining
Luke, i'm your father!!!
Ok, era uma piada... só para ter uma frase de impacto no primeiro Post publicado no blog, eh, eh!
Para que se tirem todas as dúvidas, isto não é um blog acerca da Guerra das Estrelas...
Engenheiros Web é um blog sério (?) onde se discute informática a sério (?).
Um abraço,
ESC
Ok, era uma piada... só para ter uma frase de impacto no primeiro Post publicado no blog, eh, eh!
Para que se tirem todas as dúvidas, isto não é um blog acerca da Guerra das Estrelas...
Engenheiros Web é um blog sério (?) onde se discute informática a sério (?).
Um abraço,
ESC
Subscrever:
Comentários (Atom)

